PreProcess - STI, Phase III
This page describes the automatic pre-process tasks of generating input files for STI (Semantic Type Indexing). There are two phases of this pre-process for STI:
- Phase I:
Generate all files to Java input format from Lisp files. This set of data is tested by comparing to all Lisp files and result of file.9801 and used in tc2006.
- Phase II:
use Java program to generate files from scratch (Meta-thesaurus, etc.). A new defined/refined algorithm is used to generate ST "document". This set of data is tested by comparing final files in phase I by similarity and used in tc2008.
- Phase III:
A modified version based on phase II by using Java program to generate files from scratch (Meta-thesaurus, etc.). A new refined algorithm utilized frequency, St-Groups, and STRI filter is used to generate ST "document". This set of data is tested by running through NLM's WSD collection test.
The details procedures of phase III approach is shown in the follow diagram and described as below:
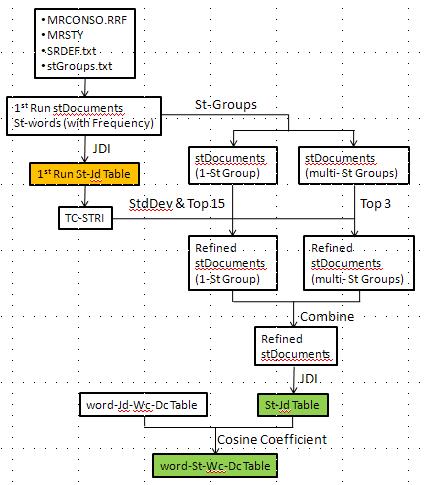
Three steps are used in STI training set to generate Word-St table.
- Generate 1st run stDocuments
- based on algorithm developed on phrase II to get all words associated with ST
- uses frequency instead using unique word
- Apply JDI on 1st run stDocuments to generate St-Jd table
- Separate 1st run stDocuments by StGroup
- 1 stGroup: for words only associate with STs that belong to only 1 stGroup
- Multi stGroups: for words associated with STs belong to multiple stGroups
- Refined stDocuments by STRI filter
STRI Filter: Run STRI on each word and check the filter criteria with the associated St. Three filter criteria are used:
- Top N rank: the rank of word associated St must be within the top N rank on the STRI result
- StdDev: the score of word associated St must be within one Standard Deviation from the top score on the STRI result
- Combination of above two criteria
- The 1st run St-Jd table is used in STRI
- From our study, we use the following criteria to reach the best result
- 1 stGroup: StdDev and Top 15 rank
- Multi stGroups: Top 3 rank
- Combine the refined stDocuments of 1-StGroup and multi-StGroup
- Generate the Word-St table
- Apply JDI on refined stDocuments to generate St-Jd table
- Get Word-Jd-Wc-Dc table from JDI
- Calculate similarity (cosine coefficient) on St-Jd table and Word-Jd-Wc-Dc table to generate Word-St-Wc-Dc table